Hand Gesture Detection & Sequence Recognition
How to detect hand gestures and train a LSTM model to recognize them
Ever wondered, what if you are able to control or send a command to your computer / mobile, by just waving some gesture in front of the camera? Or translating your hand signs into alphabets or words? Wouldn’t that be cool? Today in this article, I’m going to share my idea on how to do that, with codes provided for most parts.
What I will be going through:
- Overall approach / idea
- Data preparation
- Hand key-points detector & Feature extractor
- LSTM model training
- Model Deployment
Let’s go~
Overall Idea and Approach
In this example, I’m going to do a total of 10 different combination of hand signs, each hand signs would translate into different actions.

So meaning if I do a sign of [palm, ok, peace] sign in-front of my camera, it will trigger an action. After understanding the concept, you can actually change the gesture combination, change the number of gesture sequence and integrate output to any actions you want: music control, game control, internet browser control, smart home system, etc.
Step 1: Raw Data Preparation
Now to the tedious part, we will need to prepare a set of training data to train our sequence model, LSTM in this case. Record a lot of videos of individual signs, which later we can stitch the videos all together for training.
To improve the robustness of your model, we want to incorporate few variations in your data, hence we will be recording with varying length i.e. 2 to 6 seconds, swap between left and right hand, gesture in different positions and ways.
When we are done with each hand gestures, we then stitch individual hand gestures together according to our combinations defined in previous section.
Step 2: Hand Key-points Detector
We want to use a hand detector that is able to tell us all key-points or landmarks of your finger joints accurately, with as few computational power as possible.

We have tried the following 2 pre-trained hand detectors: OpenPose and Mediapipe, and I will be sharing my experience below.
OpenPose
OpenPose is a popular human body pose detector that does well. OpenPose has an individual hand detector module that works good, can be used through a Python API, however… you need to tell the API where is the hand located. Ortegatron has actually explained the issue quite well here, so I will be putting a reference there (https://ortegatron.medium.com/into-the-problem-of-hand-recognition-da30797450fe).
In summary, when you run full package of OpenPose, it will first detect body keypoints, then based on body parts (arm), it will extract part of image containing hand candidates and feed into a hand keypoint detector, so it will not work if it doesn’t see a body. If we want to run standalone OpenPose’s hand detector, we need to manually feed the hand’s bounding box to it.

So we do not recommend using OpenPose. If you want to stick to OpenPose’s hand detector, you could pre-defined a fix region and only do show your gesture within the region only, or train a separate region proposal model for hand (which kinda defeat the purpose of using a pre-trained hand tracker)
Mediapipe
Mediapipe (by Google), on the other hand (pun intended), has an excellent hand detector. It runs faster (even can achieve 30fps on CPU), more robust and able to work standalone compared to OpenPose. We will be using Mediapipe in our project here. For more info, do refer to https://google.github.io/mediapipe/solutions/hands.html.
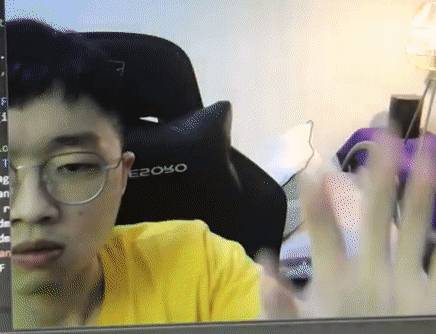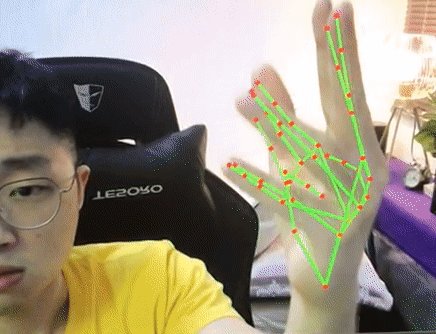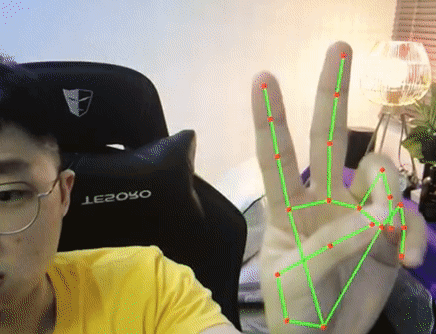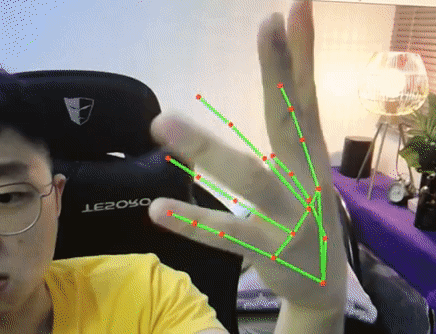
Try it with your webcam with the code below and make sure it works. In our implementation, we will be setting maximum hand to detect is 1. Hence when we initialize mp_hands class we will do with max_num_hands = 1.
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands# For webcam input:
cap = cv2.VideoCapture(0)
with mp_hands.Hands(max_num_hands=1,
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as hands:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = hands.process(image)# Draw the hand annotations on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
image, hand_landmarks, mp_hands.HAND_CONNECTIONS)
cv2.imshow('MediaPipe Hands', image)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
If you want to see how your hand gesture video clips are being detected by mediapipe hand detector, you can just do below, instead of cv2.VideoCapture(0) which uses your web camera.
video = "Insert video path here"
cap = cv2.VideoCapture(video)Now, if everything is working, let’s move on to the next step: Extract the hand landmark location and extract features from it.
Step 3: Hand Key-points Reading
Before we can extract feature, we need to be able to read the landmark points from mediapipe. If there is hand detected in frame,
from google.protobuf.json_format import MessageToJson
import jsonresults = hands.process(frame)
if results.multi_hand_landmarks:
jsonObj = MessageToJson(results.multi_hand_landmarks[0])
lmk = json.loads(jsonObj)['landmark']
print(lmk) #lmk = hand's landmark
Hand’s landmark “lmk” would extract all 20 key points, each key points has x, y and z (depth data inferred from training data) normalized location point.

[{‘x’: 0.5483812, ‘y’: 0.4468381, ‘z’: -9.817535e-05}, {‘x’: 0.4964248, ‘y’: 0.3246908, ‘z’: -0.019871125}, {‘x’: 0.43311393, ‘y’: 0.23853464, ‘z’: -0.058383696}, {‘x’: 0.38517937, ‘y’: 0.21672069, ‘z’: -0.09549859}, {‘x’: 0.35864294, ‘y’: 0.24601518, ‘z’: -0.1380672}, {‘x’: 0.36925137, ‘y’: 0.31387216, ‘z’: -0.04632774}, {‘x’: 0.32161534, ‘y’: 0.2416246, ‘z’: -0.106320135}, {‘x’: 0.33978996, ‘y’: 0.15453272, ‘z’: -0.172552}, {‘x’: 0.3715087, ‘y’: 0.09964049, ‘z’: -0.22180456}, {‘x’: 0.37630647, ‘y’: 0.38870192, ‘z’: -0.065068126}, {‘x’: 0.33675826, ‘y’: 0.31886253, ‘z’: -0.10949046}, {‘x’: 0.35534814, ‘y’: 0.23813893, ‘z’: -0.1733931}, {‘x’: 0.38720247, ‘y’: 0.18407586, ‘z’: -0.2288523}, {‘x’: 0.40031946, ‘y’: 0.4680707, ‘z’: -0.08401818}, {‘x’: 0.36856255, ‘y’: 0.40003777, ‘z’: -0.12535292}, {‘x’: 0.38593385, ‘y’: 0.32028502, ‘z’: -0.1691924}, {‘x’: 0.41574615, ‘y’: 0.27164322, ‘z’: -0.2000296}, {‘x’: 0.4313374, ‘y’: 0.5453956, ‘z’: -0.10554698}, {‘x’: 0.4186879, ‘y’: 0.46740034, ‘z’: -0.13909568}, {‘x’: 0.43700722, ‘y’: 0.39871758, ‘z’: -0.157066}, {‘x’: 0.46120787, ‘y’: 0.3604012, ‘z’: -0.17147385}]Step 4: Build a Feature Extractor from Key Points
Now that we are able to extract all key point’s location (including depth info), let’s design a feature extractor for it. At this point of time, we should not use the x,y,z key points as training as it will be tough for model learn from key points location’s movement.
So, we have hand crafted a scale-invariant and rotation-invariant feature extractor, embedding distance information from various pairs of key points.
def distance_between(p1_loc, p2_loc):
jsonObj = MessageToJson(results.multi_hand_landmarks[0])
lmk = json.loads(jsonObj)['landmark']
p1 = pd.DataFrame(lmk).to_numpy()[p1_loc]
p2 = pd.DataFrame(lmk).to_numpy()[p2_loc]
squared_dist = np.sum((p1-p2)**2, axis=0)
return np.sqrt(squared_dist)
def landmark_to_dist_emb(results):
jsonObj = MessageToJson(results.multi_hand_landmarks[0])
lmk = json.loads(jsonObj)['landmark']
emb = np.array([
#thumb to finger tip
distance_between(4,8),
distance_between(4,12),
distance_between(4,16),
distance_between(4,20),
#wrist to finger tip
distance_between(4,0),
distance_between(8,0),
distance_between(12,0),
distance_between(16,0),
distance_between(20,0),
#tip to tip (specific to this application)
distance_between(8,12),
distance_between(12,16),
#within finger joint (detect bending)
distance_between(1,4),
distance_between(8,5),
distance_between(12,9),
distance_between(16,13),
distance_between(20,17),
#distance from each tip to thumb joint
distance_between(2,8),
distance_between(2,12),
distance_between(2,16),
distance_between(2,20)
])
#use np normalize, as min_max may create confusion that the closest fingers has 0 distance
emb_norm = emb / np.linalg.norm(emb)
return emb_normThis distance embedding will be in the shape of (20,) array, capturing distance information from one key point to another key point, to detect various finger action i.e. thumb bending, each finger tip to thumb, each finger tip to each other, etc.
Step 5: Prepare Training Data
Next, stitch your gesture videos and rename your video with the class label in this format: “yourvideoname_1.mp4” where “1” is the class label.
Run the feature extractor on your stitched gesture videos with code below:
arr = os.listdir(‘Video Folder here/’)video_class_all = []
landmark_npy_all = []handnn = mp_hands.Hands( max_num_hands=1, min_detection_confidence=0.6, min_tracking_confidence=0.6)for idx,eachVideo in enumerate(arr):
landmark_npy_single = []
video = ‘Video Folder here/’+ eachVideocap = cv2.VideoCapture(video)
video_class_all.append(int(video.split(‘_’)[1]))while cap.isOpened():
success, image = cap.read()
if not success:
breakimage = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = handnn.process(image)image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
landmark_npy_single.append(landmark_to_dist_emb(results))landmark_npy_all.append(landmark_npy_single)
cap.release()
if ((idx+1) % 10)==0:
print(f’Finished for {(idx+1)} videos’)
print(f”Finished for total {len(arr)} videos. Completed.”)
Now you will get landmark_npy_all that carry list of embedding arrays and video_class_all that carry list of corresponding class labels.
Next, because we need our training data input to be of a fixed length, in this project we will set max length to be 50 embedding sequences for our LSTM model. We will need to do some trimming or padding on our embedding arrays, depending on each video’s length. If embedding length is > 50, we will apply skipping logic and if it is <50, we will do padding to 50.
from keras.preprocessing.sequence import pad_sequences
import mathdef skip_frame(landmark_npy_all, frame= 50):
new_lmk_array = []for each in landmark_npy_all:
if len(each) <= frame:
#if its less than frame, dont need to skip
new_lmk_array.append(each)else:
#skip frame by ceiling
to_round = math.ceil(len(each)/frame)
new_lmk_array.append(each[::to_round])
return new_lmk_arraynew_lmk_array = skip_frame(landmark_npy_all)
train_x = pad_sequences(new_lmk_array, padding=’post’, maxlen=max_len, dtype=’float32')
Process the skip frame logic above to ensure all your embedding arrays for training are of 50 length. In summary, what we are trying to do in this step is illustrated below.
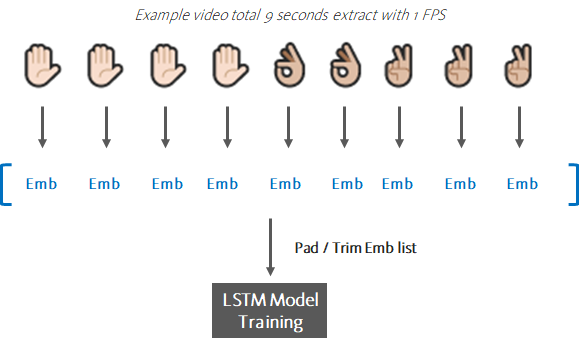
Step 6: LSTM Model Training
Make sure all parameters for input data are correct and perform train test split on our training data.
classes = len(set(video_class_all))
feature_len = 20
max_len = 50#hot encode output
train_y = to_categorical([i-1 for i in video_class_all])
print(‘Training y with shape of: ‘, train_y.shape)X_train, X_test, y_train, y_test = train_test_split(train_x, train_y, test_size=0.2)
I have about 1500 training data, hence the shape result:

Let’s construct the model with a Learning Rate scheduler that steps down at a pre-defined epoch steps:
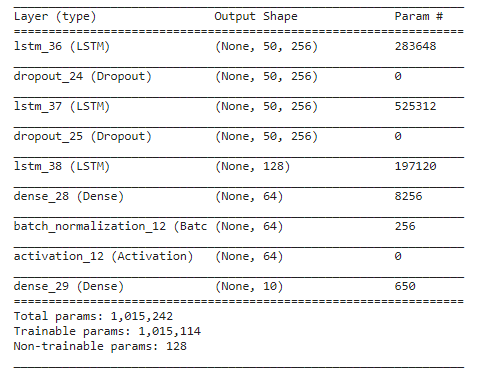
model = Sequential()model.add(LSTM(256, return_sequences=True, input_shape=(max_len, feature_len)))
model.add(Dropout(0.25))
model.add(LSTM(256, return_sequences=True))
model.add(Dropout(0.25))
model.add(LSTM(128, return_sequences=False))
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation(‘relu’))
model.add(Dense(classes, activation=’softmax’))model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])model.summary()def lrSchedule(epoch):
lr = 0.001
if epoch > 200:
lr *= 0.0005
elif epoch > 120:
lr *= 0.005
elif epoch > 50:
lr *= 0.01
elif epoch > 30:
lr *= 0.1
print('Learning rate: ', lr)
return lrLRScheduler = LearningRateScheduler(lrSchedule)
callbacks_list = [LRScheduler]
verbose, epochs, batch_size = 1, 300, 8
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs=epochs, batch_size=batch_size, verbose=verbose, shuffle=True,callbacks = callbacks_list)We are setting epochs to be 300 with 8 batch size. A few hyper parameters were searched but it may work differently for your case, so try to play around.
For this, we were able to achieve 91% of accuracy with validation data.

Step 7: Deployment
Note that for deployment, you will also need to ensure fixed input size into the LSTM model. Hence, for deployment we have a queue container with size of 50 objects to store the distance embedding. Once the queue container is filled with 50 objects, it will be sent for inference. If after a “x” amount of seconds, queue is unable to be filled to 50 objects, then it will be padded and sent for inference. Also, our camera FPS is set at 10FPS.
Conclusion
This is the end of my sharing on my hand gesture detection + hand gesture sequence recognition with LSTM model. I hope it helps in your project.
I’m contented with the result of 91% of accuracy, but of course I have also noticed several mistake in recordings of my hand gestures in training data which can certainly impact the model performance.
There are certainly many area of improvements in this project. For example, the feature extractor that I designed will not be able to extract spatial or motion information. For instance, if you do a “palm” swiping from left to right, the feature extracted will likely to stay relatively constant throughout, since it is still a “palm”, and the feature doesn’t entail any info on the motion.
Any doubts/question/suggestion, please feel free to reach out to me! Thanks for reading!